昨天簡單的介紹了缺失值的處理,今天來探討異常值的處理方式,資料在蒐集的過程中除了有遺失的狀況,當然也有記錯的可能,這些值可能會影響模型的判斷,造成準確度不佳,因此這些狀況的處理也是資料預處理中的一個步驟。
一般來說,異常值就是偏離樣本整體數據的值。包括離群值(Outlier)、噪音(Noise)...等。
噪音是一個觀測值中出現的隨機錯誤或是偏差;而離群值的發生原因有可能是真實資料所產生的,也有可能是噪音所造成的,因此對異常資料進行處理前,需要先辨別出到底哪些是真正的資料異常。
●人為失誤:在記錄數據時,可能多計或少計一個0而造成異常值。
●測量誤差:測量儀器或工具所造成的異常。
●抽樣錯誤:在抽樣時不小心抽到不同族群的資料而造成的異常。
●自然異常值:異常值的發生非人為錯誤,而是數據使然,這類的異常值就需要單獨挑出來做分析。
Ex: 健康檢查的體溫資料中出現不合常理的人類體溫(69度、負值...)就可以判定為明顯的異常。
利用資料的平均值、四分位距、標準差...等統計方法判斷資料異常
Ex: 品質管理中的3σ 原則
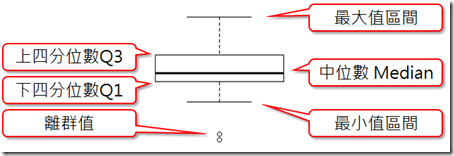
圖片來源:https://pulipuli.tumblr.com/post/152953556768/%E4%BB%8A%E5%A4%A9%E4%B8%8A%E8%AA%B2%E7%9A%84%E6%99%82%E5%80%99%E8%80%81%E5%B8%AB%E6%95%99%E4%BA%86%E7%AE%B1%E5%9E%8B%E5%9C%96box-plot%E7%9B%92%E5%9E%8B%E5%9C%96%E7%9B%92%E9%AC%9A%E5%9C%96%E5%8F%AF%E4%BB%A5%E6%9C%89%E6%95%88%E6%AF%94%E8%BC%83%E4%B8%8D%E5%90%8C%E8%B3%87%E6%96%99%E9%9B%86%E7%9A%84%E5%88%86%E4%BD%88%E6%88%91%E7%A0%94%E7%A9%B6
我們一樣使用鐵達尼號資料集來做程式示範,資料集可以參考前一天的資料。
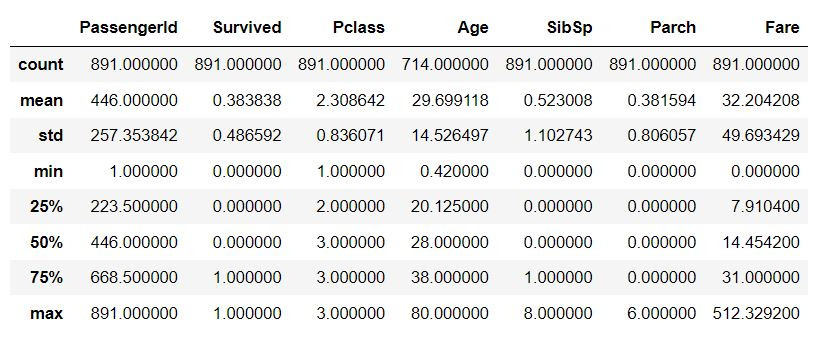
train_df.describe()
import numpy as np
# 創建一個函數,計算在這個資料中, x:資料,times : 幾倍標準差,找出在這樣條件下的異常值。
def outliers_z_score(x,times):
mean_x = np.mean(x)
stdev_x = np.std(x)
z_scores = [(i - mean_x) / stdev_x for i in x]
return np.where(np.abs(z_scores) > times)
out_index=outliers_z_score(train_df['Age'],3)
print(train_df.loc[out_index[0],'Age']) #列出異常值以及index

import seaborn as sns
import matplotlib.pyplot as plt
features=["Pclass","Age","SibSp","Parch","Fare"] #要觀察的特徵
fig , ax = plt.subplots()
fig.subplots_adjust(hspace=1, wspace=0.6)
location=1
for i in features:
plt.subplot(2, 3, location) #畫布位置
sns.boxplot(data=train_df,x=i) #盒鬚圖
location+=1
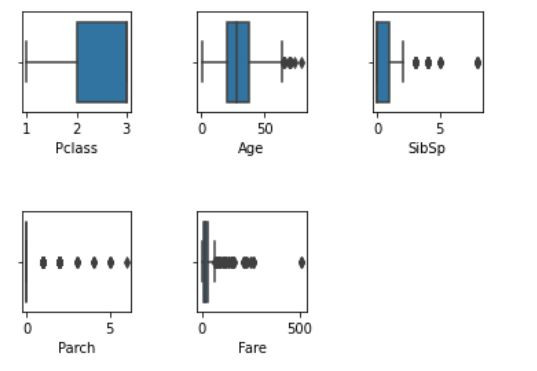
異常值的出現,對於是否該刪除或是保留,要根據應用性質與領域知識而定,舉個例子來說,我們可以看到上面的範例中,"Fare"的異常值看似很多,但票價的範圍可能本來就是這麼大,我們沒有可輔助的資訊去判斷這個異常值是否正常,但假如我們能夠取得"Pclass"(艙等)個等級的票價範圍,我們就可以用這個資訊當輔助去判斷,假如一位客人買的是低等艙,但他的票價卻是高等艙的票價,這筆資料可能就會有所問題,因此異常值判斷並不是程式coding出來就好,更重要的是判斷資料以及找到支持自己立場的佐證!

